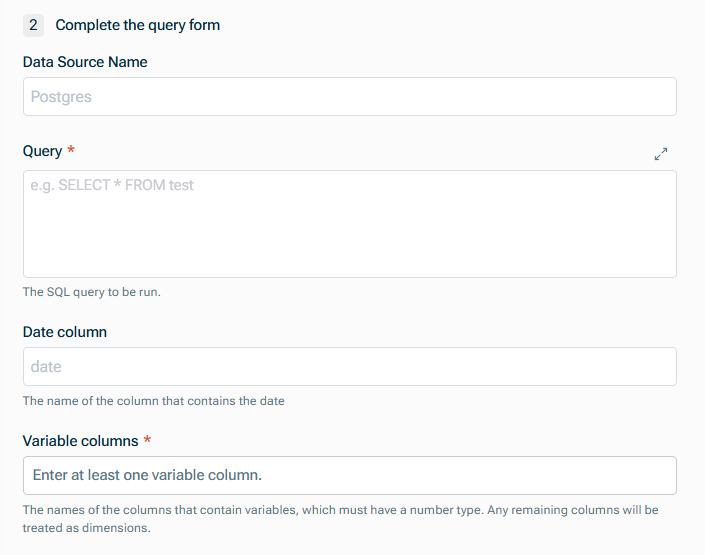
Konfigurieren Sie die Schritte wie im folgenden Abschnitt beschrieben.
Verbindung zu Redshift herstellen
Zuletzt aktualisiert am 18.12.2025
Überblick
Sie können eine direkte Verbindung zu Redshift herstellen, um Daten in xP&A zu übernehmen. Es ist möglich, einen SSH-Tunnel für die Verbindung zu verwenden.
Dieser Artikel beschreibt die Voraussetzungen und die einzelnen Schritte der Einrichtung.
Die Felder, die übernommen werden, müssen während der Einrichtung mit einer Datenbank-Abfrage definiert werden. Eine detaillierte Anleitung zur Strukturierung einer solchen Abfrage finden Sie unter Datenbankabfragen definieren.
Dieser Artikel enthält folgende Abschnitte:
Voraussetzungen für die Einrichtung
Damit xP&A eine Verbindung zu Ihrer Redshift-Datenbank herstellen kann, müssen Sie im Vorfeld die folgenden Aktionen durchführen:
Sie müssen die folgende statische IP-Adresse auf die Whitelist setzen, bevor Sie Redshift mit xP&A verbinden: 52.59.129.235
Sie müssen sicherstellen, dass Ihre Redshift-Datenbank beim White-Listing dieser IP-Adressen nur mit einer starken Kombination aus Benutzername und Kennwort zugänglich ist. Gehen Sie wie folgt vor:
Öffnen Sie die Eigenschaften (Properties) Ihres Redshift Clusters.
Klicken Sie unter den Netzwerk- und Sicherheitseinstellungen (Network and security settings) auf die VPC-Sicherheitsgruppe (VPC security group):
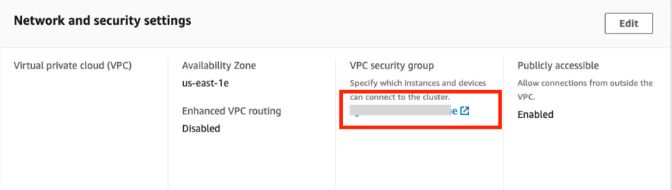
Öffnen Sie den Reiter Eingehende Regeln (Inbound rules) und klicken Sie auf Eingehende Regeln bearbeiten (Edit inbound rules):
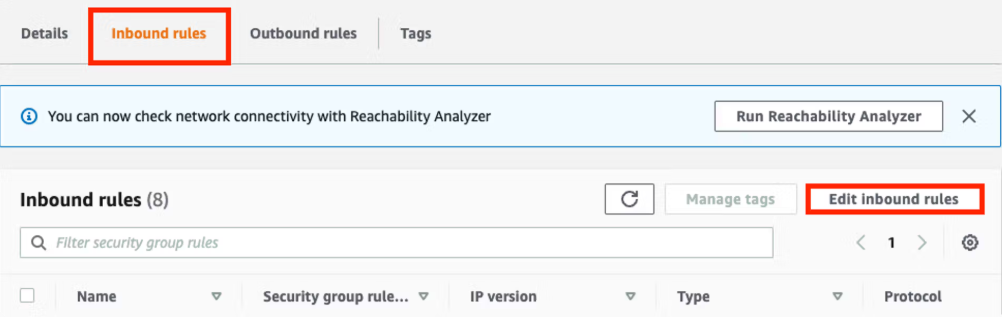
Wählen Sie als Typ (Type) die Option Redshift, geben Sie unter CIDR-Blöcke (CIDR blocks) Ihre externe IP-Adresse an und klicken Sie auf Regeln speichern (Save rules).
 IP-Adresse angeben
IP-Adresse angeben
Damit xP&A eine Verbindung zu Ihrer Redshift-Datenbank herstellen kann, müssen Sie Ihre Datenbank öffentlich zugänglich machen. Gehen Sie wie folgt vor:
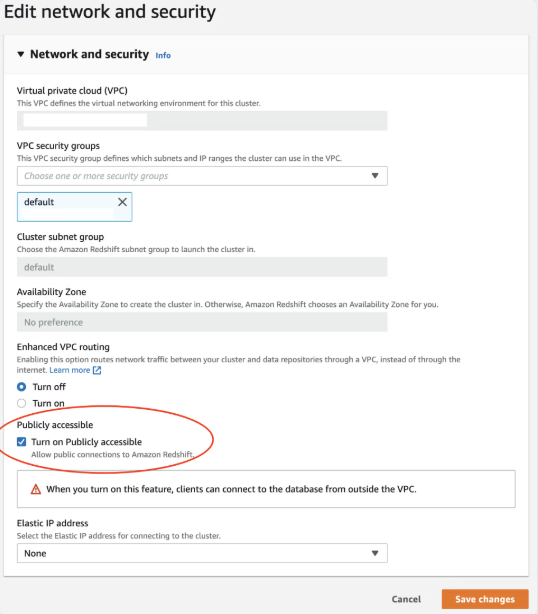
Öffnen Sie die Eigenschaften (Properties) Ihres Redshift Clusters.
Stellen Sie unter den Netzwerk- und Sicherheitseinstellungen (Network and security settings) sicher, dass die Option Öffentlich zugänglich (Publicly accessible) aktiviert ist.
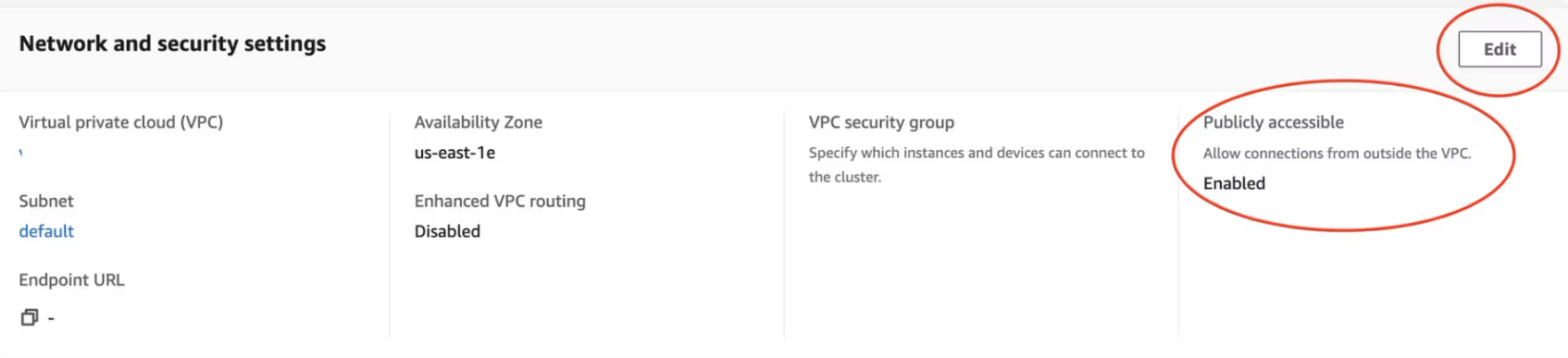
Falls diese Option nicht aktiviert ist, klicken Sie auf Bearbeiten (Edit) und aktivieren Sie die Option Öffentlich zugänglich aktivieren (Turn on Publicy accessible).
Verbindung zu Redshift herstellen
Um eine Verbindung zu Redshift herzustellen
Wählen Sie eine der folgenden Optionen:
- Öffnen Sie in der Übersicht auf der Startseite den Arbeitsbereich Daten und klicken Sie auf + Neu.
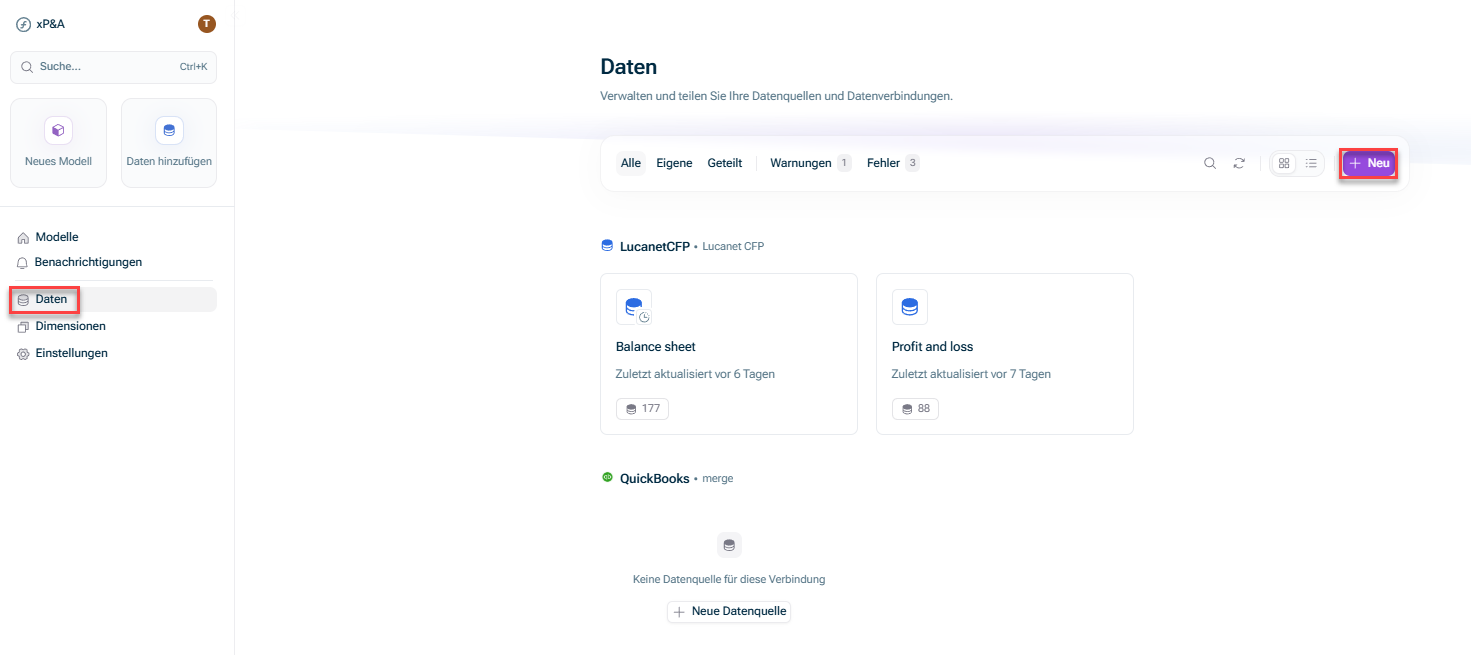
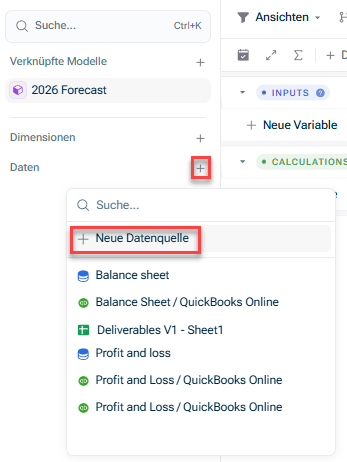
- Öffnen Sie das Modell, in das Sie die Daten integrieren möchten. Klicken Sie in der Übersicht auf das Symbol + neben Daten und wählen Sie Neue Datenquelle:
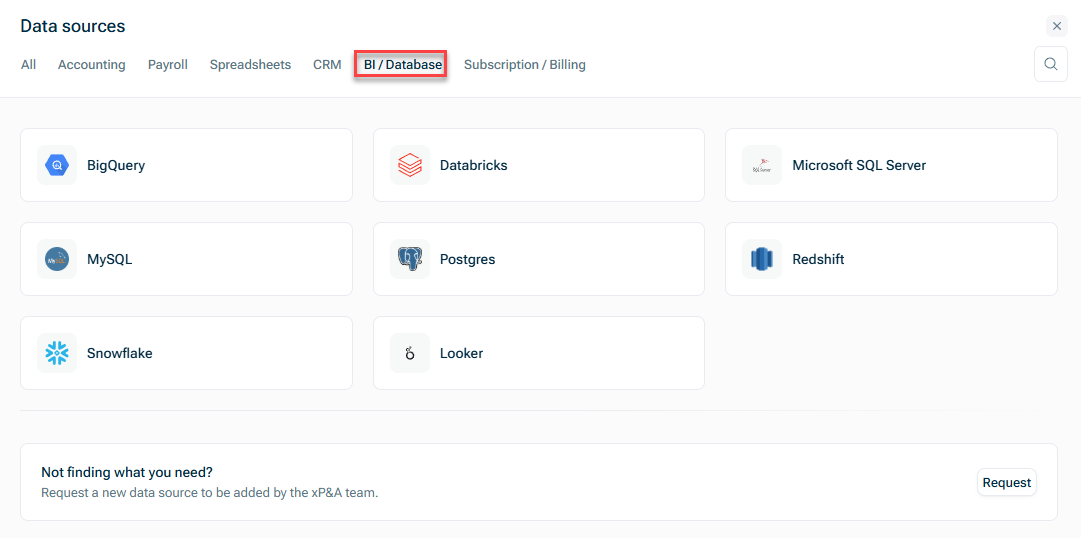
Öffnen Sie im Dialog Datenquellen den Reiter BI/Database und wählen Sie MySQL:
Der Dialog Neue Datenquelle wird wie folgt angezeigt:
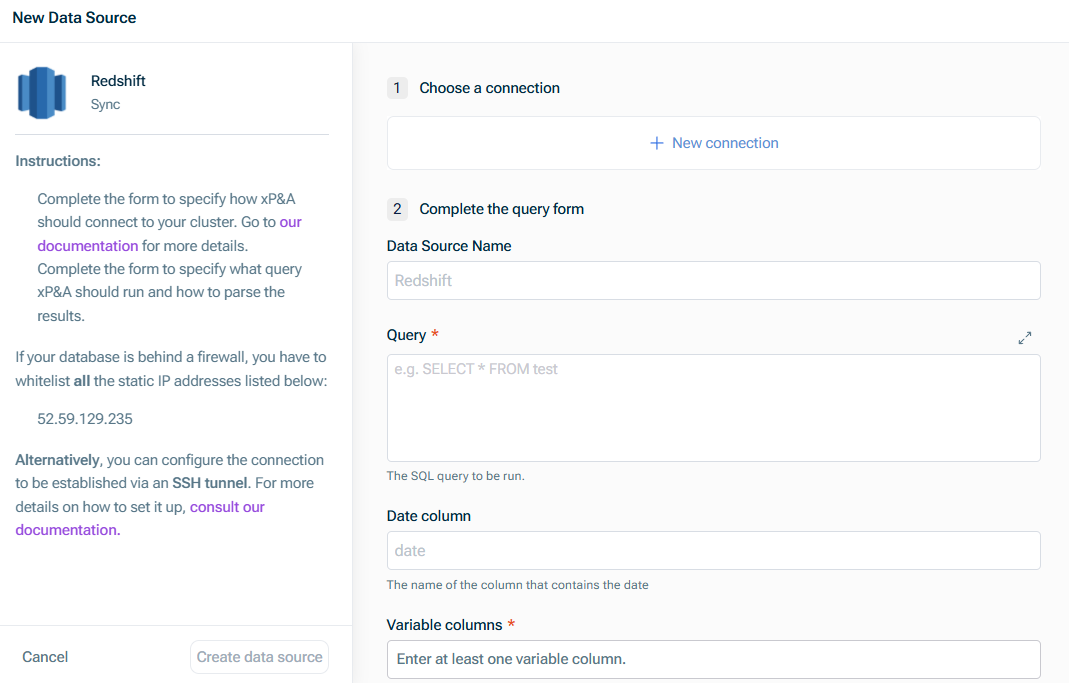
Klicken Sie auf Datenquelle erstellen.
Einrichtungsschritte
Die folgenden Schritte sind erforderlich, um die Datenquelle einzurichten:
Schritt
Beschreibung
Wählen Sie eine Verbindung
Wählen Sie eine bestehende Verbindung oder, falls Sie noch keine Verbindung konfiguriert haben, klicken Sie auf Neue Verbindung und geben Sie Folgendes im Dialog Neue Redshift-Verbindung an:
- Cluster-Endpunkt-Hostname für Redshift ohne Port und Datenbank
- Cluster-Endpunkt-Port
- Name der Datenbank, mit der Sie sich verbinden möchten
- Datenbankbenutzername und Kennwort
Die Benutzeranmeldedaten sind spezifisch für den Redshift-Cluster und nicht für AWS-Services. Weitere Informationen zum Erstellen und Verwalten von Datenbankbenutzern im Redshift Cluster finden Sie in der Redshift-Dokumentation.
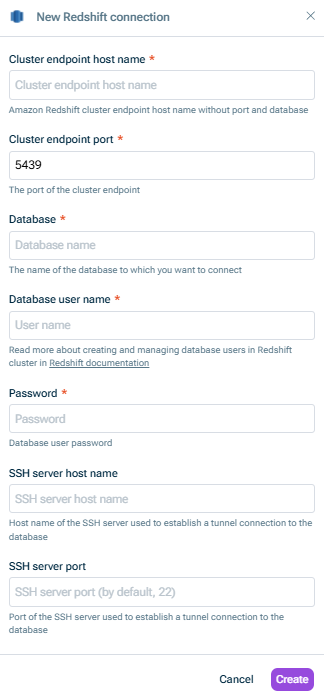
Wenn Sie eine Verbindung über einen SSH-Tunnel herstellen möchten, geben Sie zusätzlich Folgendes an:
- Hostname des SSH-Servers, der zum Aufbau einer Tunnelverbindung zur Datenbank verwendet wird
- Port des SSH-Servers, der verwendet wird, um eine Tunnelverbindung zur Datenbank herzustellen
Wenn Sie den Zugriff auf Ihr Data Warehouse über SSH konfigurieren:
- Stellen Sie sicher, dass Sie die Voraussetzungen für die Einrichtung erfüllen.
- Denken Sie daran, den Datenbank-Host-Namen auf die interne IP-Adresse Ihrer Datenbank im Netzwerk zu aktualisieren.
- Wenn Sie eine bestehende Verbindung auf SSH aktualisieren möchten, wenden Sie sich bitte an uns.
Füllen Sie das Abfrageformular aus
Geben Sie Folgendes an:
- Name der Datenquelle
- Abfrage, um die Felder zu definieren, die übernommen werden sollen. Weitere Informationen finden Sie unter Datenbankabfragen definieren.
- Name der Datumsspalte, die eines der Redshift-Datumsformate sein muss
- Namen der Spalten, die Variablen enthalten (die einen numerischen Datentyp haben müssen)
Alle verbleibenden Spalten werden als Dimensionen behandelt und müssen einen string-Datentyp haben.
Eine Ausnahme ist die Kohorten-Dimension, die ein Datum sein muss, wobei die Spaltenüberschrift explizit als Kohorte gekennzeichnet werden muss.