What's New im XBRL Tagger?
Entdecken Sie jetzt alle neuen Features unserer Lösung XBRL Tagger!
Die Versionen aller Lösungen, die Sie aktuell verwenden und die der CFO Solution Platform werden Ihnen angezeigt, wenn Sie in der CFO Solution Platform im Menü Hilfe den Menüpunkt Über Lucanet ausführen.
-
XBRL Tagger
-
XBRL Vision
Zuletzt veröffentlichte Features
Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterungen:
Continuation Administration
Sie können Fortsetzungsketten (Continuation chain) nun direkt im Web Tagger verwalten. Wenn sich ein mit Tags versehener Textblock über mehrere Abschnitte eines Dokuments erstreckt, werden die einzelnen Abschnitte zu einer Fortsetzungskette verknüpft. Über den neuen Dialog Continuation Administration können Sie die gesamte Kette an einem Ort einsehen und verwalten.
Multipanel-Modus
Ab sofort kann im XBRL Tagger ein Multipanel-Modus aktiviert werden, der es ermöglicht, bis zu drei Panels nebeneinander zu öffnen. Den Multipanel-Modus können Sie z. B. aktivieren, um Taxonomie, Validierungsergebnisse und Fact Properties parallel zu öffnen und zu bearbeiten. Der Wechsel zwischen Einzel- und Multipanel-Modus ist über einen Schieberegler möglich.
Hidden Facts
Sie können im Web Tagger jetzt XBRL-Werte erfassen und taggen, die nicht als sichtbare Elemente im Quelldokument vorhanden sind. Diese Funktion ist besonders für Berichte relevant, in denen bestimmte Werte gemeldet werden müssen, die nicht explizit im Dokument stehen. Die neue Hidden Facts-Ansicht zeigt alle Hidden Facts des aktuell geöffneten Dokuments in einer Tabelle an. In der Ansicht können Sie Werte hinzufügen und diese per Drag & Drop aus der Taxonomie zuweisen.
Hidden Facts sind Teil der Dokumentvalidierung und des iXBRL-Exports: Sie werden bei der XBRL-Validierung berücksichtigt und in das iXBRL-Report-Package aufgenommen.
Fußnotenverwaltung
Mit der neuen Fußnotenverwaltung können Fußnoten als eigene Tags erfasst und mit den entsprechenden Tabellenzellen oder Textstellen verknüpft werden, um die Nachvollziehbarkeit und maschinelle Auswertbarkeit zu erhöhen.
Tabellenübergreifende Tag-Navigation in der Berechnungsansicht
In der Linkbase Berechnung zeigt der XBRL Tagger jetzt, welche Summanden in anderen Tabellen desselben Berichts verwendet werden: Diese Summanden sind mit einem hellroten Hintergrund und einem roten Informationssymbol hervorgehoben. Klicken Sie auf das Symbol oder das Label, um direkt zur entsprechenden Tabelle und Zelle zu navigieren. So prüfen Sie tabellenübergreifende Tag-Beziehungen auf einen Blick und erkennen Tagging-Inkonsistenzen schnell.
What's New im XBRL Tagger?
Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterungen:
Neue Rollen für den XBRL Tagger
Der XBRL Tagger verfügt nun über eigene, vom Disclosure Management unabhängige Benutzerrollen. Die folgenden Rollen sind verfügbar:
- Administrator: Hat vollständigen Einblick in alle Dokumente des Unternehmens und kann alle Aktionen ausführen.
- Bearbeiter: Die Standardbenutzerrolle. Kann in Dokumenten arbeiten, die er selbst erstellt hat oder zu denen er eingeladen wurde.
Bestehende Benutzer werden automatisch in die neuen Rollen migriert:
- Disclosure Management-Administroren werden zu XBRL-Administratoren
- Benutzer mit einer anderen Disclosure Management-Rolle werden zu XBRL-Bearbeitern.
Die Rollen eines Benutzers werden Plattform-Arbeitsbereich Administration unter Benutzer angelegt und bearbeitet.
Neben Fehlerbehebungen, Stabilitäts- und Performance-Verbesserungen und Design-Anpassungen enthält die neue Version folgende Erweiterungen:
Ebenen (Layer)
Im XBRL-Tagger können ab sofort Ebenen beim Tagging verwendet werden. Tagging-Ebenen ermöglichen es, denselben Textbereich mehrfach mit unterschiedlichen Tags zu versehen – da sich Tags innerhalb einer Ebene nicht überlappen dürfen, wird für überlappende Tagging-Bereiche einfach eine zusätzliche Ebene angelegt. Das ist z. B. dann relevant, wenn ein Textabsatz mit zwei verschiedenen Taxonomieelementen getaggt werden muss.
Mit dem Ebenen-Manager verwalten Sie die Tagging-Ebenen eines Dokuments. Die Standard-Ebene ist immer vorhanden und kann nicht gelöscht werden. Ebenen, auf denen sich Tags befinden, werden im Ebenen-Manager markiert.

Text- und Tabellen-Tagging auf separaten Reitern
Im XBRL-Tagger stehen ab sofort zwei separate Reiter zur Verfügung: Text-Tagging und Tabellen-Tagging. Bisher war das Taggen von Textinhalten nur möglich, wenn zuvor ein Content Control im Dokument angelegt wurde. Mit der Trennung in Text- und Tabellen-Tagging entfällt dieser Schritt: Textblöcke lassen sich jetzt direkt im XBRL-Editor markieren und taggen. Gleichzeitig sorgt die getrennte Ansicht dafür, dass Text-Tags und Tabellen-Tags nicht mehr gegenseitig die Sicht auf den Inhalt verdecken.
Auf dem Reiter Text-Tagging können Sie Textblöcke in Word-Dokumenten direkt im Editor markieren und mit einem XBRL-Tag versehen. Die Textauswahl erfolgt per Klicken und Ziehen. Über Anfasser am Anfang und Ende der Auswahl lässt sich der markierte Bereich nachträglich anpassen.
Auf dem Reiter Tabellen-Tagging, können die Zellen von Tabellen gezielt markiert und getaggt werden.

Berechnungen
Berechnungen (Calculations) sind eine regulatorische Anforderung: In XBRL-Berichten müssen mathematische Beziehungen zwischen Finanzkennzahlen als sogenannte Calculation-Linkbases hinterlegt sein. Damit wird dokumentiert, aus welchen Elementen sich ein Summenwert zusammensetzt – zum Beispiel Total Assets = Current Assets + Non-Current Assets. Prüfer und Regulatoren erwarten diese Angaben als Bestandteil eines validen XBRL-Reports. Im XBRL-Tagger steht ab sofort dafür die Berechnungsansicht (Calculation-View) zur Verfügung. Wenn Sie eine Zelle in einem Dokument anklicken, die eine Berechnung enthält, werden die zugehörigen Details angezeigt: Ob die berechnete Summe mit dem gemeldeten Wert übereinstimmt, wird unmittelbar durch eine Farbkodierung angezeigt: Grün bedeutet Übereinstimmung, Rot bedeutet Abweichung. Im Fall einer Abweichung wird zusätzlich der Delta-Wert (absolute Differenz) eingeblendet.
Die Berechnungsansicht schafft Transparenz über die mathematischen Strukturen im XBRL-Report und ermöglicht es, Abweichungen frühzeitig zu erkennen – bevor der Bericht eingereicht wird. Damit werden Validierungsfehler bei der regulatorischen Einreichung vermieden.
Vollständige Details anzeigen
In der Berechnungsansicht ist zusätzlich die Option Vollständige Details verfügbar. Wenn Sie diese Option aktivieren, werden für jeden Summanden zusätzliche technische Informationen angezeigt:
- Geparster Wert (Parsed Value): Der numerische Wert, den der XBRL-Tagger direkt aus dem Quelldokument ausgelesen hat – noch vor der Anwendung von Vorzeichen oder Gewichtung. So lässt sich prüfen, ob der Tagger die Zahl korrekt interpretiert hat.
- Technischer Name (Technical Name): Der Bezeichner des zugeordneten Taxonomie-Elements. Dies ist besonders dann relevant, wenn in einer Taxonomie mehrere Elemente identische Anzeigebezeichnungen tragen – zum Beispiel bei deutschen ESEF-Übersetzungen, bei denen unterschiedliche Elemente denselben deutschen Begriff verwenden.
Die Detailansicht zeigt diese Informationen ausschließlich für die Summanden, nicht für den Summen- oder Gesamtwert. Die Farbkodierung (Grün/Rot) für die Validierung bleibt auch in der Detailansicht erhalten. Die Detailansicht richtet sich insbesondere an XBRL-Spezialisten und interne Prüfer. Sie ermöglicht eine lückenlose Nachvollziehbarkeit der Berechnungslogik und erleichtert die Prüfdokumentation. Abweichungen lassen sich gezielt auf fehlerhafte Werteauslesung oder Vorzeichenlogik zurückführen.

Tabelle wählen im Dialog 'Reihenfolge der Tabellenzeilen'
Beim Taggen von Tabellen können Sie mithilfe der Funktion Zeilenreihenfolge die Reihenfolge der Tabellenzeilen anpassen. Diese Funktion wurde jetzt wie folgt optimiert: Im Dialog Reihenfolge der Tabellenzeilen können Sie über eine Dropdown-Liste ganz einfach zwischen den Tabellen in Ihrem Dokument wechseln. Sobald Sie eine Tabelle aus der Dropdown-Liste wählen, werden automatisch die entsprechenden Zeilen für die gewählte Tabelle angezeigt:

Diese Verbesserung optimiert Ihren Arbeitsablauf, da Sie die Zeilenreihenfolge über mehrere Tabellen hinweg verwalten können, ohne zum Dokument zurückkehren zu müssen. Lucanet XBRL Tagger schützt Ihre Arbeit außerdem durch Warnungen bei ungespeicherten Änderungen beim Wechseln zwischen Tabellen und stellt so sicher, dass keine Änderungen verloren gehen.
Taxonomie automatisch zuordnen
Beim Hochladen eines Dokuments mit bestehendem Tagging wird jetzt automatisch eine passende Taxonomie vorgeschlagen und im Dialog Neues Dokument hinzufügen angezeigt. Die vorgeschlagene Taxonomie können Sie bei Bedarf manuell ändern.
Anpassungen aus Reporting Manuals
Die geänderten und erweiterten Anforderungen, z. B. aus den ESMA 2025 Reporting Manual wurden im XBRL Tagger umgesetzt und können dort angewendet werden.
Ältere Versionen
Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterungen:
Lokale GAAP-Berichtsanforderungen für Italien, Singapur und Malaysia hinzugefügt
Beim Hinzufügen einer Berichtsanforderungen können Sie nun die GAAP-Berichtsanfoderungen für Italien, Singapur und Malaysia wählen. Das System konfiguriert diese Berichtsanforderungen automatisch mit Classic-XBRL-Formateinstellungen und gewährleistet so die sofortige Einhaltung lokaler regulatorischer Mandate. Diese Erweiterung ermöglicht es Ihnen, in diesen Jurisdiktionen konforme XBRL-Berichte zu generieren, die ihre spezifischen lokalen GAAP-Anforderungen ohne zusätzliche Konfiguration erfüllen.
Anzeige des XBRL-Berichtstyps in den Dokumentinformationen
Beim Wählen von Berichtsanforderungen wird Ihnen ab sofort auch die Berichtsart angezeigt, d. h. ob eine Berichtsanforderung ein Inline XBRL-Package (iXBRL) oder ein Classic XBRL-Package generiert. Diese schreibgeschützte Information wird für jedes Dokument auf dem Reiter Information angezeigt:

Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterungen:
- Neugestaltung des Informationsfensters: Das neue Layout ersetzt das bisherige durch eine optimierte Benutzeroberfläche, sodass kein Scrollen und kein manuelles Speichern mehr erforderlich ist.
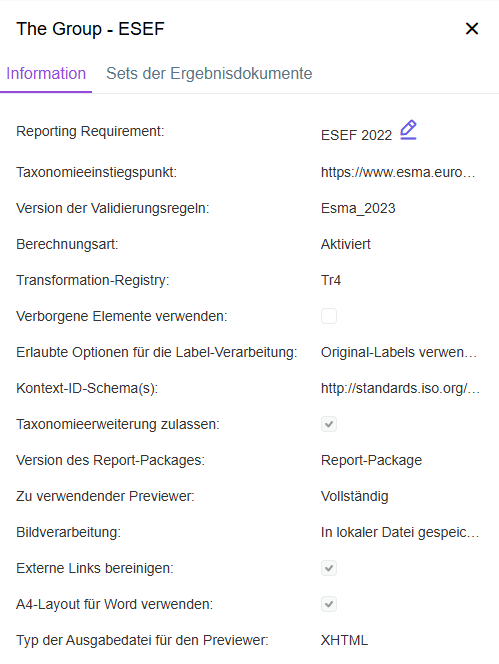 Anzeige der Informationen zu einem Dokument
Anzeige der Informationen zu einem Dokument
- Anzeige von Ergebnisdokumenten: Die Ergebnisdokumente zu einer Datei werden jetzt in der Dokumentübersicht im Fenster rechts auf dem Reiter Sets der Ergebnisdokumente angezeigt. Mit Umgestaltung können Sie Ergebnisdokumente einfach erweitern, reduzieren und herunterladen, wodurch das Auffinden und Verwalten von Dateien, die aus einem Dokument generiert wurden, vereinfacht wird.
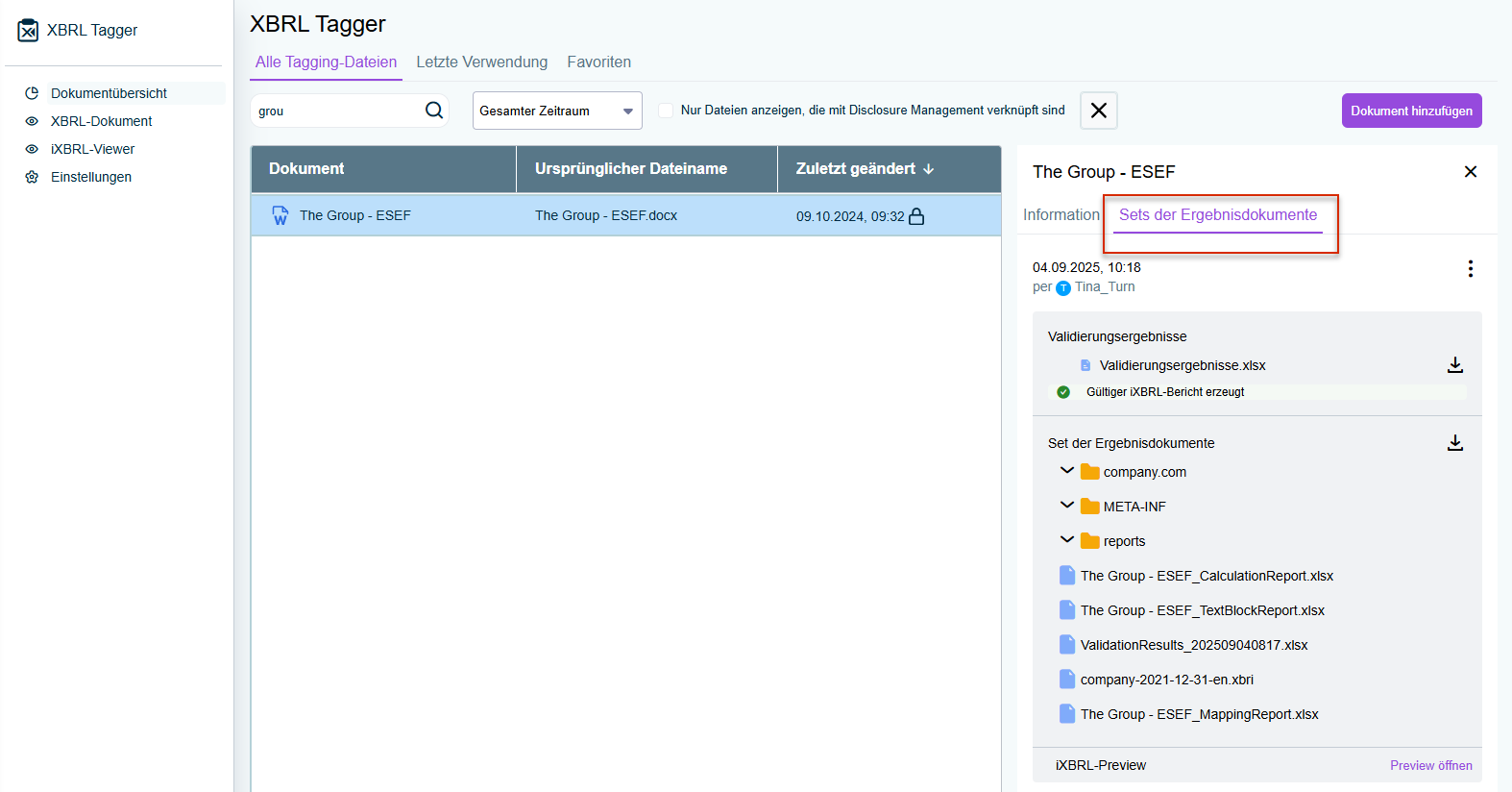 Anzeige der Ergebnisdokumente in der Dokumentübersicht
Anzeige der Ergebnisdokumente in der Dokumentübersicht
- Favoriten und zuletzt verwendete Dateien: Zu den zusätzlichen Funktionen gehört die Möglichkeit, Dateien als Favoriten zu markieren und zuletzt aufgerufene Dokumente nach Aktualität sortiert anzuzeigen, um einen schnelleren Zugriff auf häufig verwendete Dateien zu ermöglichen.
- Neue Symbole: Ab sofort ist das Format eines Dokuments im XBRL Tagger anhand eines eindeutigen Symbols klar erkennbar. Z. B. haben Word- und Disclosure Management-Dokumente ein eindeutiges und erkennbares Symbol. Das Symbol wird neben dem Dokument in der Dokumentübersicht sowie in der Tagging-Ansicht angezeigt.
- Primäre Taxonomie festlegen: Die primäre Taxonomie in den Einstellungen wird jetzt automatisch entsprechend des gewählten Reporting-Requirements festgelegt. Sowohl für Disclosure Management- als auch für Nicht-Disclosure-Management-Dateien kann die automatisch gewählte primäre Taxonomie nicht geändert werden und wird grau dargestellt.
- Automatisches Setzen von Reporting Requirements: Wenn Sie ein Dokument aus Disclosure Management in den XBRL Tagger übernehmen, muss ab sofort das Reporting Requirement nicht mehr manuell zugewiesen werden. Der XBRL Tagger setzt das entsprechende Reporting Requirement jetzt automatisch.
Das einem Dokument zugewiesene Reporting Requirement können Sie in der Dokumentübersicht auf dem Reiter Information erkennen, sobald Sie in der Übersicht ein Dokument markieren.
Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterung:
Flexible Zeilenreihenfolge für Erweiterungstaxonomien
Ab sofort können Sie die Reihenfolge der Einträge in Erweiterungstaxonomien anpassen, wenn Sie Tabellen in einem dafür vorgesehenen Dialog mit Tags versehen. Klicken Sie auf die Schaltfläche Zeilenreihenfolge im Ribbon-Menü und ordnen Sie die Zeilen per Drag-and-Drop neu an. Sie können die Reihenfolge der Zeilen auch auf die Basistaxonomie zurücksetzen, indem Sie auf die Schaltfläche Zeilenreihenfolge der Basistaxonomie verwenden klicken. Mit dieser Option können Sie die Reihenfolge der Einträge auf die ursprüngliche Reihenfolge aus der Basistaxonomie zurücksetzen, sodass Sie Ihre Datenstruktur bei Bedarf leichter anpassen können.
Wenn die Reihenfolge in Ihrer Erweiterungstaxonomie bereits der Basistaxonomie entspricht, wird die Schaltfläche Zeilenreihenfolge der Basistaxonomie verwenden automatisch deaktiviert.

Dokument im Cockpit von DisclosureManagement öffnen
Sobald ein Dokument aus Disclosure Management in den XBRL Tagger importiert wurde, kann das verknüpfte Dokument direkt aus der Dokumentübersicht des XBRL Tagger im Cockpit von Disclosure Management geöffnet werden.
Außerdem kann die Dokumentübersicht nach Dokumenten gefiltert werden, die mit Disclosure Management verknüpft sind.

Neben Fehlerbehebungen sowie Stabilitäts- und Performance-Verbesserungen enthält die neue Version folgende Erweiterung:
KVK-Taxonomie laden und verwenden
Die KVK-Taxonomie kann jetzt in den XBRL-Tagger geladen und verwendet werden. Die Unterstützung der XBRL-Validierung für die KVK-Taxonomie folgt in einem zukünftigen Update.
Lucanet XBRL Vision: XBRL-Daten analysieren
Lucanet XBRL Vision ist ein neues kostenloses webbasiertes Tool zur professionellen Analyse von XBRI/ZIP-Packages, das sofortige Validierung und Visualisierung ohne Datenupload oder Installation ermöglicht. Es richtet sich an Finanzexperten, Auditoren und Regulierungsbehörden und gewährleistet vollständigen Datenschutz durch Verarbeitung direkt im Browser. Lucanet XBRL Vision finden Sie unter der URL https://vision.platform.lucanet.cloud/vision.
Die Haupteigenschaften von Lucanet XBRL Vision sind:
- Datenschutz: Das Tool benötigt keine Registrierung oder Installation und verarbeitet alle Daten lokal im Browser, wodurch die Privatsphäre der Benutzer und die Daten vollständig geschützt bleiben.
- Benutzerfreundlichkeit: Navigieren Sie mit einer intuitiven, professionellen Benutzeroberfläche durch Ihre Inline-XBRL-Berichte. Tag-Elemente, ihre Beziehungen und Hierarchien werden übersichtlich visualisiert.
- Umfangreiche Analysefunktionen: Lucanet XBRL Vision bietet die interaktive Visualisierung von Inline XBRL-Berichten, technische und geschäftliche Validierung gemäß XBRL 2.1 und unterstützt Standards wie ESEF.
- KI-freundliche Datenaufbereitung: Das Tool konvertiert XBRL-Daten in strukturierte JSON-Formate, optimiert für große Sprachmodelle und moderne Datenpipelines, um erweiterte Analysen und Integration zu ermöglichen.