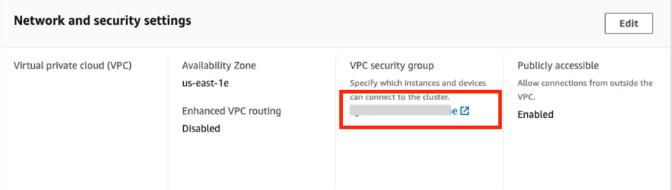
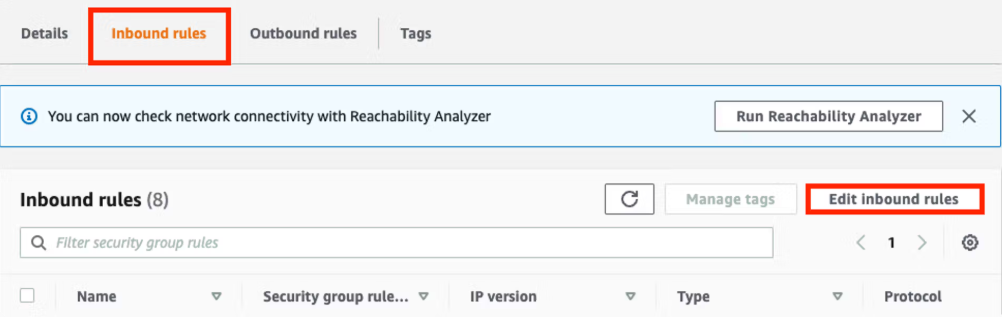

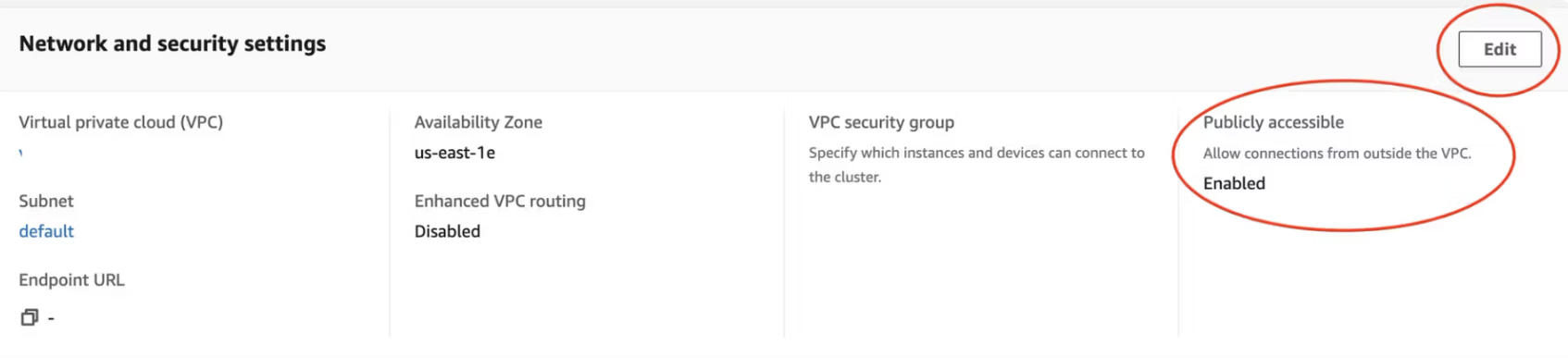
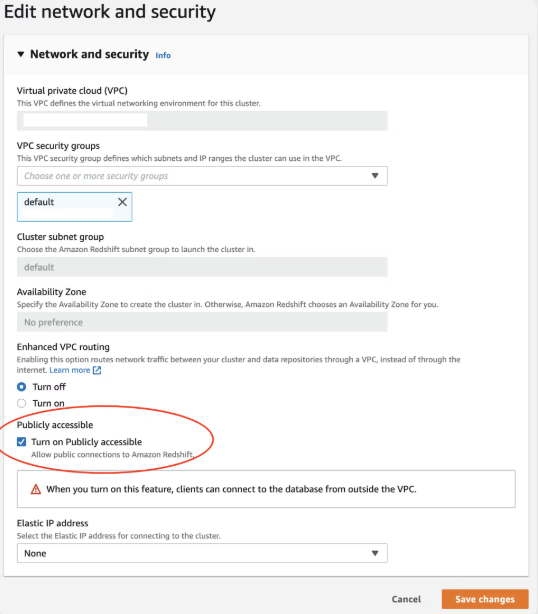
Öffnen Sie in der Übersicht auf der Startseite den Arbeitsbereich Daten + Neu
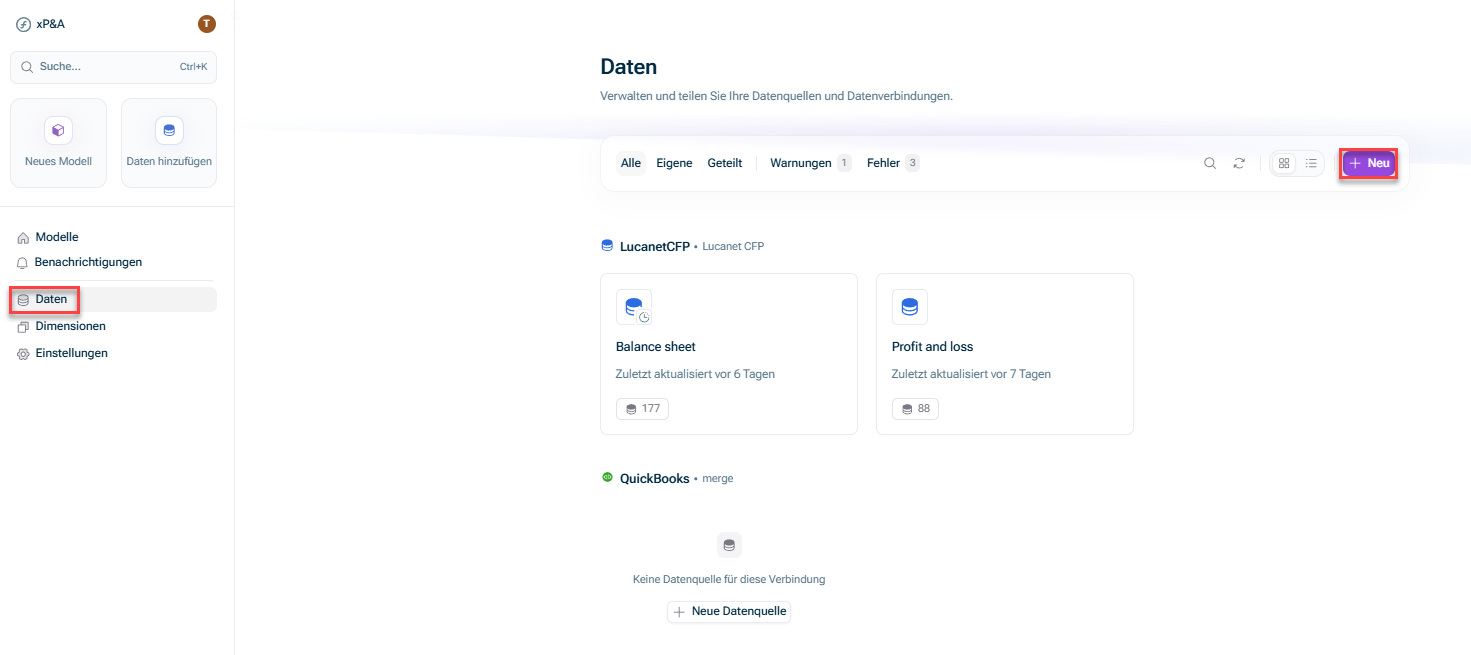
Öffnen Sie das Modell, in das Sie die Daten integrieren möchten. Klicken Sie in der Übersicht auf das Symbol + Daten Neue Datenquelle
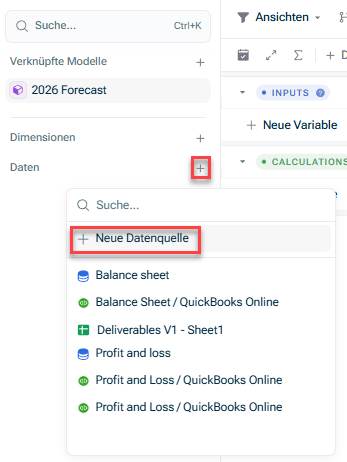
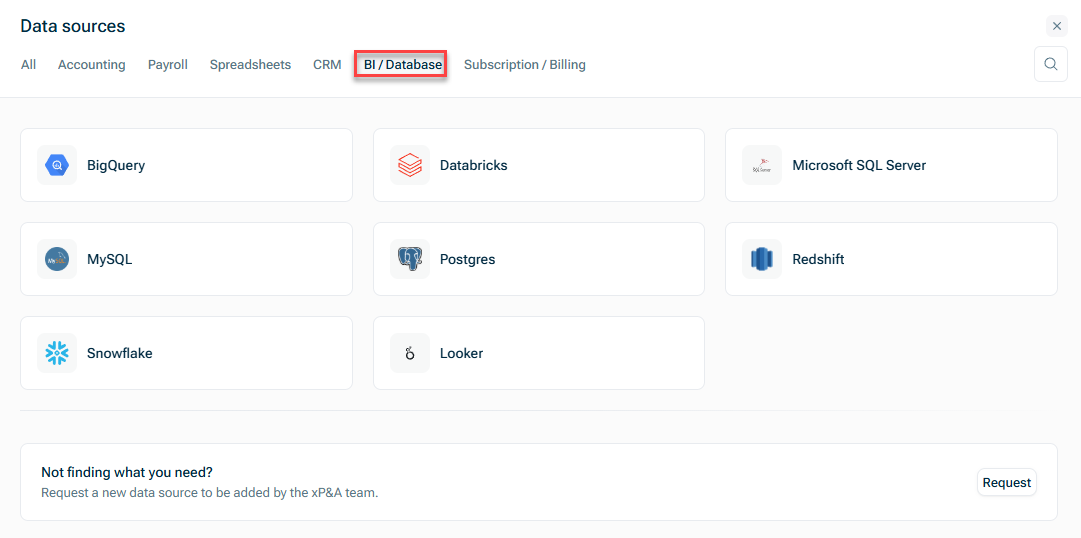
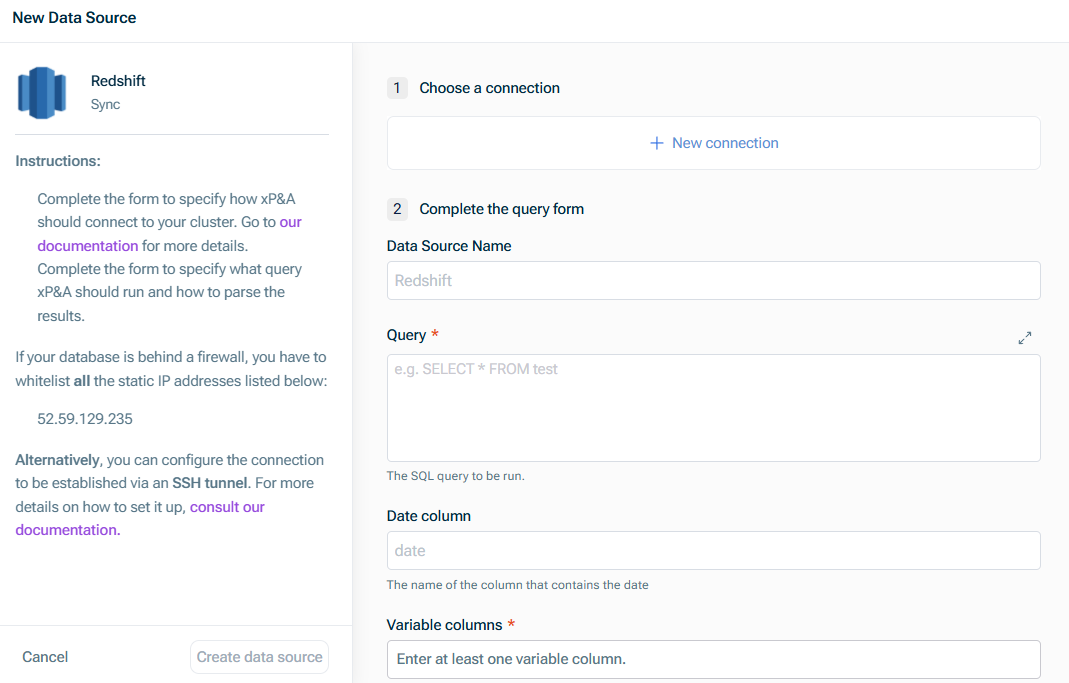
Wählen Sie eine Verbindung
Cluster-Endpunkt-Hostname Cluster-Endpunkt-Port Name der Datenbank Datenbankbenutzername Kennwort
Hostname des SSH-Servers, der zum Aufbau einer Tunnelverbindung zur Datenbank verwendet wird Port des SSH-Servers, der verwendet wird, um eine Tunnelverbindung zur Datenbank herzustellen
Stellen Sie sicher, dass Sie die Voraussetzungen für die Einrichtung erfüllen. Denken Sie daran, den Datenbank-Host-Namen auf die interne IP-Adresse Ihrer Datenbank im Netzwerk zu aktualisieren. Wenn Sie eine bestehende Verbindung auf SSH aktualisieren möchten, wenden Sie sich bitte an uns.
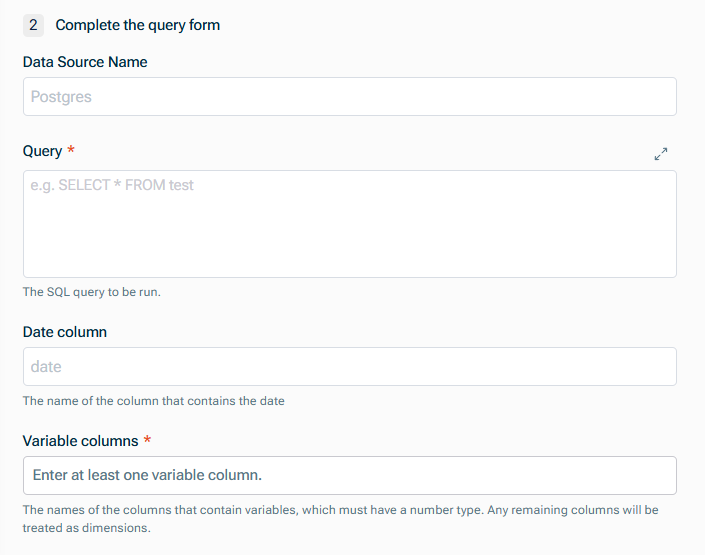
Füllen Sie das Abfrageformular aus
Name der Datenquelle Abfrage Datenbankabfragen definieren Name der Datumsspalte Namen der Spalten, die Variablen numerischen
Zuletzt aktualisiert am 01.05.2026